Supervised Learning
In this chapter you'll be introduced to:
- Supervised Learning: Understanding how to formulate supervised learning tasks and the components involved.
- Regression Problems: Focusing on regression where the target variable is continuous.
- Machine Learning Systems: The steps involved in building a machine learning model, including defining hypotheses and selection criteria.
- Hypothesis Class and Overfitting vs. Underfitting: Why specifying a hypothesis class is essential and the trade-offs in model complexity and their impact on performance.
What is Supervised Learning?
Supervised Learning is a type of machine learning where the model is trained using labeled data. The goal is to learn a function that maps inputs, , to desired outputs, , based on example input-output pairs. Our training dataset is a list of pairs , called training samples, where is the index into the training set. More precisely, we can define our training data consisting of examples:
- : Input vector for the -th example.
- : Target output for the -th example.
Formulating a Supervised Learning Task
To formulate a supervised learning task, we need to:
- Define the Input Variables (): Features or attributes used to make predictions.
- Define the Target Variable (): The outcome we want to predict.
- Specify the Task: For example, predicting the weight of an animal based on its size and fur texture.
Each task requires a specific target variable and input features. The formulation depends on the problem we aim to solve.
Input Features
The input in supervised learning is denoted as , a vector of features known during both training and prediction. These features can be:
- Real Numbers: Continuous values like size, weight, or temperature.
- Categorical Variables: Discrete categories like animal type or color.
If we have features, the input vector is:
Categorical features cannot be directly used in mathematical models. We need to convert them into numerical representations.
One-Hot Encoding
One common method is one-hot encoding, where each category is represented by a binary vector.
- Example: Animal Type (Cat, Dog, Elephant)
- Cat: [1, 0, 0]
- Dog: [0, 1, 0]
- Elephant: [0, 0, 1]
This avoids assigning arbitrary numerical values that could imply an unintended order or magnitude between categories.
We'll see other representations in latter chapters.
Output Targets
The target variable is denoted as (also denoted as in the literature). Depending on its nature, supervised learning tasks are classified as:
- Regression: If is a real number (continuous).
- Classification: If is a category from a finite set.
In these first few chapters, we'll focus on regression problems.
Regression Problems
In regression, the goal is to learn a function that maps input features to a continuous output. The regression model is denoted as , where:
- : The number of input features.
- : The predicted output for input .
Given a new input , the model predicts the target as:
Building a supervised learning model involves several steps:
1. Defining the Hypothesis Class
Humans define a set of possible models (functions) that the machine learning algorithm can choose from. This set is called the hypothesis class, denoted as .
- Limiting the hypothesis class prevents the model from fitting noise in the training data, i.e., overfitting.
- Without restrictions, the model could choose any function, making learning from finite data impossible.
Overfitting
When a model is too complex, it fits the training data very well but performs poorly on new data.
- Cause: Hypothesis class is too powerful (too many functions).
Underfitting
When a model is too simple, it cannot capture the underlying pattern of the data.
- Cause: Hypothesis class is too limited.
In this step, we need to find a balance where the model is complex enough to capture the data patterns but simple enough to generalize well.
In this example we show how a polynomial function would fit to data with different degrees of freedom. If the class is too strict (on the left) the function underfits the data. If the class is too powerful (on the right) the function overfits.
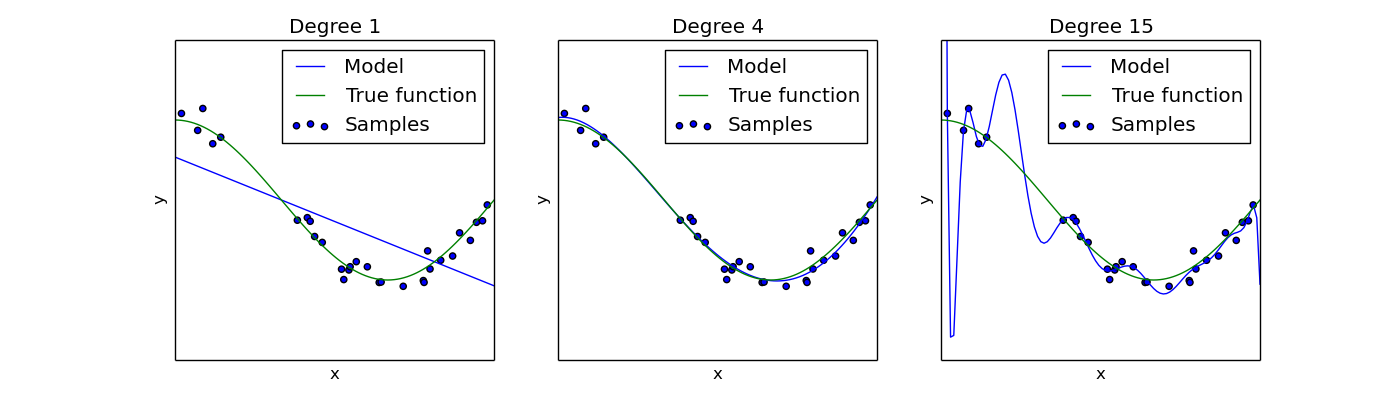
2. Defining the Selection Criterion
Humans specify a selection criterion (objective function) that evaluates how well a model fits the training data. Denoted as , it's a function of the hypothesis and the training data.
Our goal is to find the hypothesis that minimizes .
3. Training the Model
The machine learning algorithm selects the best hypothesis from by minimizing the selection criterion:
4. Making Predictions
With the trained model , predictions are made on new, unseen data :
5. Evaluating the Model
The model's performance is evaluated using a measure of success or error function on unseen data:
The objective is to assess how well the model generalizes to new data.
- Note: is often different from the training criterion .
Recap
1. What is the primary goal of supervised learning?
2. What does the training dataset in supervised learning consist of?
3. In regression problems, what does the model predict?
4. What is the hypothesis class in a supervised learning model?
5. Why is defining a hypothesis class important in supervised learning?
What's Next
In the next chapter, we'll go through Linear Regression, a fundamental learning algorithm in supervised learning.
Footnotes
-
Portions of this page are reproduced from work created and shared by Scikit-learn and used according to terms described in the BSD 3-Clause License. ↩