Bounding-Box Inference for Error-Aware Model-Based Reinforcement Learning
I replicated the results presented in this paper. The codebase can be found in this GitHub repository (in python).
The original codebase for the paper can be found in this GitHub repository (in C++).
This content is a summary and includes my personal takeaways from the paper "Bounding-Box Inference for Error-Aware Model-Based Reinforcement Learning" by Talvitie et al. It reflects the points I found most relevant, along with my own conclusions on the topics discussed.
For a more comprehensive understanding of the topics and to align with the authors' perspectives, please READ THE PAPER.
Introduction
Model-Based Reinforcement Learning (MBRL) aims to learn a model of the environment dynamics to reduce sample complexity and potentially improve policy performance. Let
be a Markov Decision Process (MDP), where is the state space, is the action space, is the transition distribution, is the reward function, and is the discount factor. The goal is to find a policy that maximizes the expected discounted return
In MBRL, the agent simultaneously learns a model that approximates and uses it to simulate state-action transitions. Naively treating simulated rollouts as ground truth can mislead the value function and degrade the policy. This problem is particularly acute when the model has insufficient capacity, when the hypothesis space is inadequately explored, or when training samples are limited.
The paper defines:
-
Aleatoric uncertainty as the inherent randomness in the environment. This uncertainty is irreducible—no amount of additional data or model refinement can eliminate it.
-
Epistemic uncertainty as the uncertainty over the model parameters due to limited data. Unlike aleatoric uncertainty, epistemic uncertainty is reducible through additional data.
-
Model inadequacy as the error arising from a model’s structural limitations or oversimplifications. This type of uncertainty cannot be fully resolved merely by acquiring more data; it requires a fundamental revision of the model.
Selective planning aims to mitigate catastrophic planning by weighing model-based value targets according to their estimated reliability.
The paper uses the Model-based Value Expansion (MVE), which computes multi-step targets:
and for ,
where are generated by the model. By weighting these targets based on uncertainty, selective planning can exploit accurate predictions while ignoring harmful ones.
The paper present a novel uncertainty measure for MVE—Bounding-Box Inference (BBI). BBI infers upper and lower bounds on the multi-step targets and weights them according to the gap between these bounds.
Problem Setting and Mathematical Formulation
We consider an MDP with unknown dynamics and reward . At each time , the agent observes a state , selects an action , and receives a reward . The environment transitions to a new state .
The agent maintains a state-action value function to approximate
where
The agent also learns a model approximating and .
Selective MVE Update
Let be the weight assigned to the -step target. The selective MVE update is given by:
Let be the uncertainty measure associated with horizon . We form weights via a softmin:
where is a temperature parameter. As , the update approaches Q-learning; as , it approaches uniform weighting.
The challenge is to define the uncertainty over the simulated targets, .
Uncertainty Measures
Several uncertainty measures are compared in the paper:
-
One-Step Predicted Variance (1SPV):
1SPV estimates uncertainty by aggregating the predicted variances of one-step model predictions over the rollout. Specifically, the uncertainty at horizon is given by:where represents the predicted variance of the next state dimension , and represents the predicted variance of the reward at state and action . Although computationally efficient, this method can be overly conservative when state uncertainties do not translate directly to uncertainty in TD targets.
-
Monte Carlo Target Variance (MCTV):
This approach estimates uncertainty by sampling rollouts from the model for the same initial transition. Given samples at horizon , the mean target is defined as:
and the uncertainty is estimated as the sample variance:
This method directly estimates uncertainty over TD targets, though its accuracy depends on the number of samples and the model’s predicted distribution.
-
Monte Carlo Target Range (MCTR):
Instead of using variance, MCTR defines uncertainty as the range of the sampled targets:
This measure directly captures the spread of possible outcomes and is less sensitive to assumptions about the distribution’s shape, though it still depends on the number of samples.
-
Bounding-Box Inference (BBI):
BBI uses a bounding-box over states and actions to infer upper and lower bounds on the TD targets. Consider a bounding-box over states and over actions . Define:
Similarly, given the current state and action and the actual next transition , we define a bounding-box model rollout:
The bounding-box TD target at horizon :
where is the maximum possible value with the states and actions included. And is the least you can get with the states and actions included.
The BBI uncertainty is . This approach is distribution-insensitive and relies on conservative bounding, ensuring that no harmful scenario is overlooked. Though potentially conservative, BBI avoids catastrophic failures due to model misestimation.
Empirical Evaluation
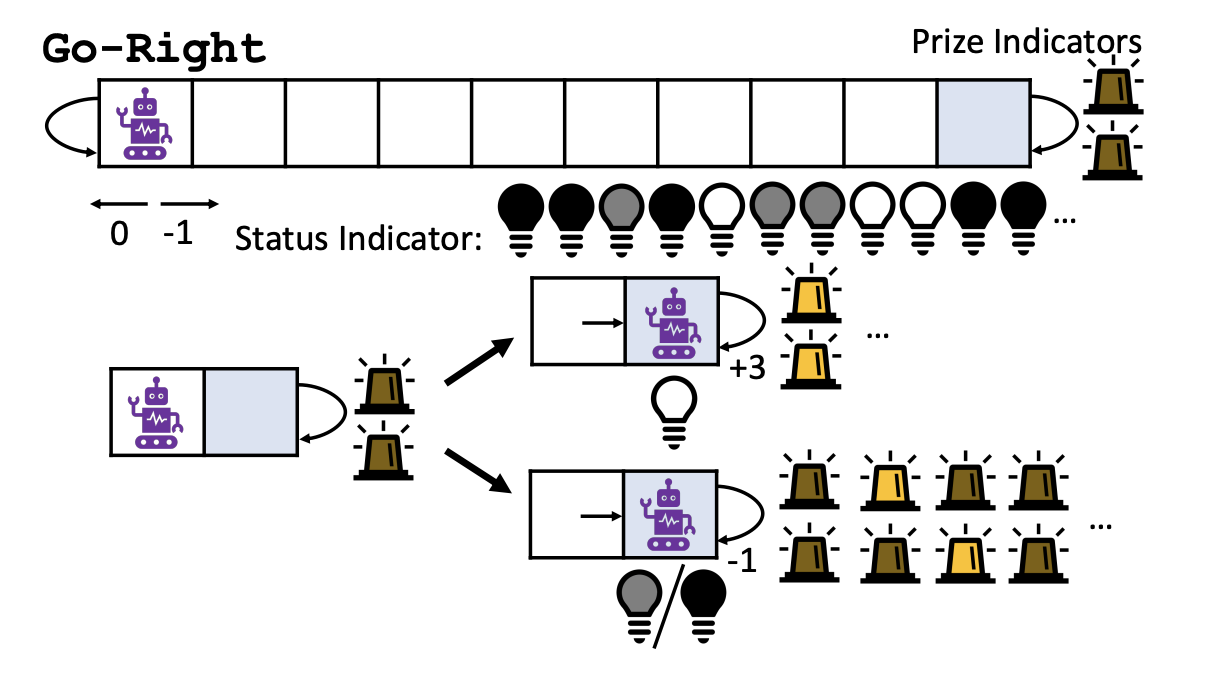
The paper evaluates uncertainty‐aware selective planning using the GoRight environment, which is designed to test exploration and planning under model error.
GoRight Environment
In the GoRight environment, the objective is to reach the rightmost position under specific conditions. The state consists of:
-
Position:
- Integer .
- Observed as a float with an offset in .
- Actions
left,rightshift the agent’s position by .
-
Status Indicator ():
- Observed with an offset .
- Follows a deterministic 2nd-order Markov pattern (defined by a transition table in the paper).
- If the agent enters position 10 while this status is at 10, the prize condition is triggered.
-
Prize Indicators ():
- Two indicators in standard GoRight, or ten in GoRight10.
- Observed with offsets .
- They are all
0outside position 10; they turn fully1(all on) only when the agent has successfully hit the prize condition (see status indicator). Otherwise, when the agent is in position 10 but has not triggered the prize, the lights cycle in a fixed pattern (all off, then only the first turns on, then only the second, and so on)
-
Rewards:
0for aleftaction.-1for arightaction unless the agent is in position 10 with all prize indicators =1, in which case therightaction yields+3.
Although the underlying dynamics are discrete, the agent receives noisy, continuous observations. This noise makes the environment partially observable; in particular, the agent does not have access to the previous status indicator value, so a perfect least-squares estimator would predict a chance of triggering the prize even when that is not the case.
Experimental Setup
The experiments are performed as follows:
-
Each training iteration consists of 500 steps of interaction and 500 steps of evaluation before the environment is reset. A total of 600 iterations (300,000 training steps) is used. The task is non-episodic; the agent does not receive termination signals, and the environment is simply reset.
-
Transitions are gathered using a uniform-random behavior policy while updates are applied based on the collected data. Evaluation is carried out using a greedy policy over 500 steps.
-
Performance is measured by the average discounted return calculated with a discount factor (typically for GoRight, with experiments also run at for sensitivity analysis).
-
For each method, a grid search is performed over the learning rate and the temperature parameter used in the softmin weighting of multi-step targets. The best configurations are selected based on the final performance (averaged over the last 100 episodes).
-
Each configuration is run for 50 independent trials. Learning curves are smoothed over a moving window of 100 episodes.
Baselines and Models
The paper compares several baselines and model variants to assess the effect of uncertainty estimation on planning:
-
Q-learning:
A standard tabular Q-learning baseline using a lookup table over discretized states. No planning or model-based simulation is used. -
Perfect Model:
Uses a hand-coded model that outputs exact predictions of the environment dynamics. This serves as an upper bound for performance. -
Expectation Model:
A hand-coded Markov model that computes the least-squares estimate of the next state and reward. While unbiased, it may fail to capture rare events (e.g., full activation of prize indicators). -
Sampling Model:
A stochastic model that provides independent samples from the maximum likelihood distribution over the next state. It captures randomness but may assign low probabilities to critical events (e.g., full activation of prize indicators). -
Linear Model:
A learned linear model that predicts changes in state and reward. It supports uncertainty estimation through output and outcome bound queries by evaluating feature extremes. (The paper describes this model but does not include its results.) -
Regression Tree:
A non-linear model trained with the Fast Incremental Regression Tree (FIRT) algorithm. Each leaf maintains statistics (mean, min, max, variance) to enable outcome bound queries. -
Neural Network:
A two-layer feed-forward network trained with the ADAM optimizer. For BBI, the network outputs both the expected outcome and quantile estimates (0.05 and 0.95), which are used to infer bounds.
Results
The experimental results are summarized as follows:
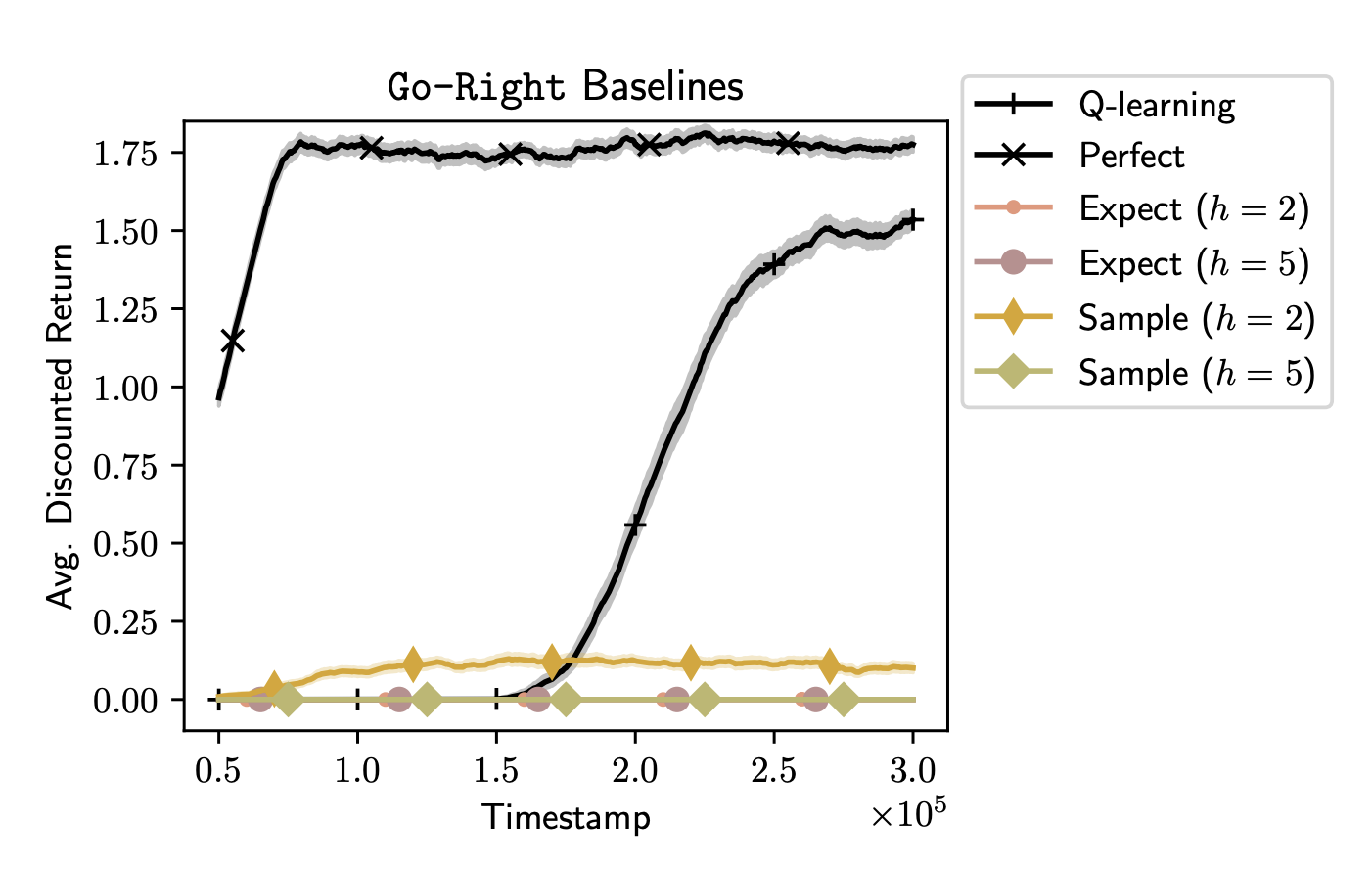
- Q-learning learns the optimal policy eventually but requires more steps, as it does not leverage any model-based planning.
- The Perfect Model shows that accurate predictions can drastically reduce the number of suboptimal actions, yielding higher returns.
- The Expectation Model may underpredict rare transitions (such as the full activation of prize indicators), leading to planning failures when the planning horizon is too long (e.g., ).
- Sampling Models capture stochasticity but often misrepresent rare events due to low-probability assignments.
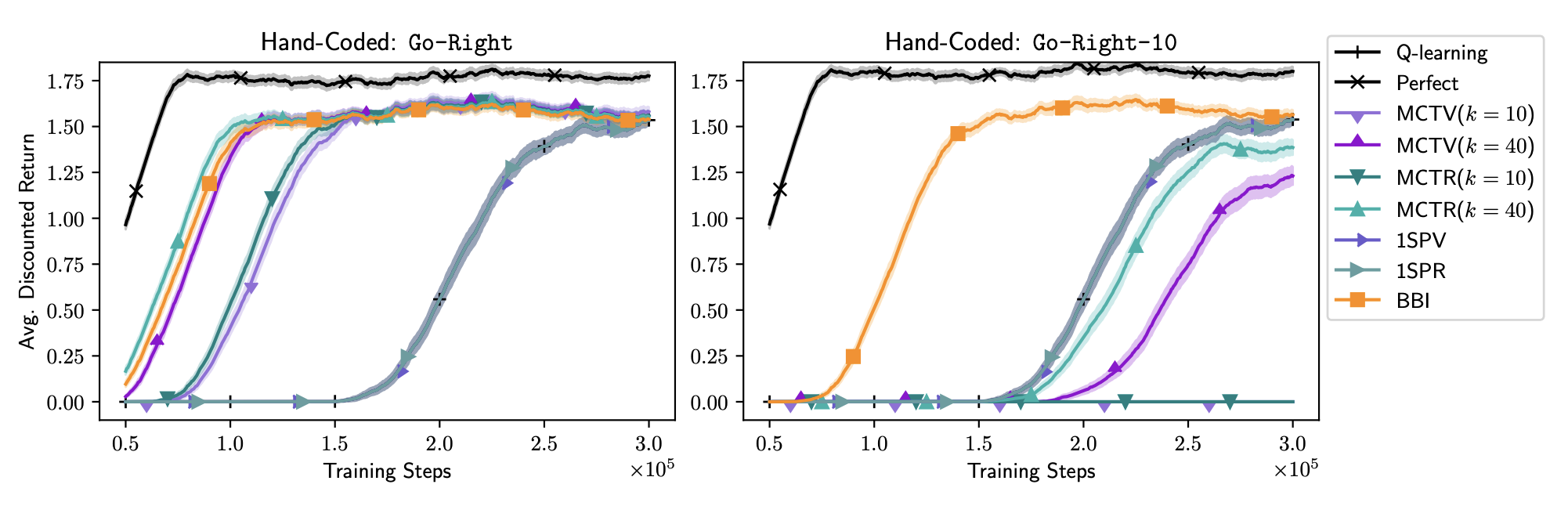
- Bounding-Box Inference (BBI):
- In the GoRight-10 variant, BBI remains robust and largely insensitive to changes in the model’s predicted probability distribution.
- However, when using learned models (especially neural networks), BBI can overestimate uncertainty due to cumulative looseness in bound propagation.
Results from learned models, discussions and conclusions will be included in a future update.
Feel free to reach out with any questions or comments. Happy experimenting!